
SQLD 1과목, 데이터 모델링의 이해
1. 주식별자가 없어도 되는 엔터티는 무엇인가?
설명: 데이터베이스 설계에서 관계엔터티는 두 개 이상의 다른 엔터티 사이의 관계를 표현하기 위해 사용됩니다.
이러한 엔터티는 별도의 주식별자를 가지지 않고, 나머지 엔터티들의 식별자를 조합하여 자신의 식별자로 사용하는 경우가 많습니다.
예를 들면 '학생'과 '과목' 사이에 '수강'이라는 관계엔터티가 있다면, '수강' 엔터티의 식별자는 '학생 ID'와 '과목 ID'의 조합으로 구성될 수 있습니다.
즉 각각의 '학생'과 '과목' 엔터티는 자신의 식별자를 가지고 있지만, 관계엔터티인 '수강' 엔터티는 별도의 주식별자 없이 두 엔터티의 식별자를 이용하여 고유하게 식별할 수 있게 됩니다.
답: 관계엔터티
2. 외부, 개념, 논리 스키마는 무엇인가
스키마는 데이터베이스의 아키텍처의 세 가지 레벨을 나타낼 수 있습니다.
이걸로 DB 디자인의 추상화 수준을 나타내며, 상황에 맞게 프로그램이 사용할 수 있게 해 줍니다.
| 외부 스키마(External Schema) | 데이터베이스 시스템의 사용자 관점을 나타냅니다. 이는 사용자별 뷰(View)로도 표현될 수 있으며, 각각의 사용자나 사용자 그룹이 데이터를 보는 방식을 맞춤화할 수 있습니다. 예를 들어, 어떤 사용자는 특정 테이블의 일부 필드만 볼 수 있도록 설정될 수 있습니다 |
| 개념 스키마(Conceptual Schema) | 데이터베이스의 전체적인 구조를 정의하고 모든 사용자가 접근하는 데이터와 그 관계를 기술합니다. 데이터베이스의 구조적 특성을 정의하는데 사용되며, 테이블, 속성, 데이터 타입, 관계 등을 포함되고 데이터베이스 관리 시스템(DBMS)에 독립적이어야 하며, 데이터베이스의 논리적 구조를 나타냅니다 |
| 내부 스키마(Internal Schema) | 데이터가 실제로 저장소에 어떻게 저장되고 조직될지를 설명하는 스키마입니다. 내부 스키마는 물리적 저장 구조, 인덱스, 액세스 경로, 파일 구조 등의 세부적인 정보를 포함하여 데이터의 물리적인 측면을 다룹니다. |
3. 데이터베이스 모델링
데이터 모델은 시스템 내에 존재하는 데이터, 데이터 간의 관계, 데이터의 의미적 세부 사항, 데이터의 일관성을 정의하는 개념적 도구
데이터 모델링은 데이터 구조를 정의하고 데이터베이스 설계를 위한 프로세스 개발하는 과정입니다.
| 개념적 모델링(Conceptual Modeling) | 가장 높은 수준의 추상화를 사용하여, 데이터베이스에 저장될 주요 정보와 그 정보들 간의 관계를 식별합니다. 개념적 모델링의 목적은 사업 영역의 주요 개념들과 그 관계를 모델링하여 이해하기 쉬운 형태로 제시하는 것으로 엔터티-관계 다이어그램(ERD)을 사용합니다. 이 다이어그램은 엔터티, 엔터티의 속성, 그리고 엔터티 간의 관계를 보여줍니다. |
| 논리적 모델링(Logical Modeling) | 개념적 모델에서 얻은 정보를 기반으로 데이터베이스의 구조를 더 자세히 정의하는 단계입니다. 이 단계에서는 데이터베이스 관리 시스템(DBMS)의 특성에 맞게 데이터를 구조화합니다. 논리적 모델은 데이터 타입, 키, 테이블, 컬럼 등을 정의하고 데이터베이스 스키마로 변환되는데, 이 정보는 데이터베이스 내에서 어떻게 데이터가 저장되고 조작될지를 결정합니다. |
| 물리적 모델링(Physical Modeling) | 물리적 모델링은 실제 데이터베이스 시스템에서 데이터를 어떻게 저장하고 관리할지를 결정하는 단계입니다. 이는 스토리지 구조, 액세스 방법, 인덱싱 전략 등을 포함하며, 데이터베이스의 성능과 효율성을 최적화하는 데 중점을 둡니다. 물리적 모델은 DBMS의 기능을 최대한 활용하여 구현되며, 보안, 백업, 복구 전략도 이 단계에서 고려됩니다. |
4. 부모엔터티의 조건
부모 엔터티가 되는 조건 다음과 같다.
- 기본 키 보유: 부모 엔터티는 인스터스내에서 구별하기 위해 기본 키를 가져야 함
- 자식 엔터티와의 관계: 부모 엔터티는 하나 이상의 자식 엔터티의 관계를 맺습니다, 자식의 외래키를 통해 참조됨
- 무결성 제약 조건 유지: 부모와 자식 엔터티의 관계는 무결설 제약 조건, 특히 참조 무결성을 유지해야 한다 예를 들면 자식 엔터티에 있는 모든 외래키 값은 반드시 부모 엔터티의 기본 값 중 하나와 같아야 한다.
- 삭제 및 갱신 전파 관리: 부모 엔터티의 특정 레코드가 삭제되면 그것과 연결된 자식 엔터티도 해당 필드가 반영될 수 있어야 함
5. 식별, 비식별 문제
| 항목 | 식별자관계 | 비식별자관계 |
| 목적 | 강한 연결관계 표현으로 레코드를 유일하게 식별할 수 있도록 보장하는 하나 이상의 속성으로 구성함, 일반적으로 기본키(Primary Key)를 사용 |
약한 연결관계 표현으로 두 개 이상의 열이 결합하여 고유한 식별자를 생성하지만 개별적으로는 식별되지 않는 경우를 말함, 일반적으로 외래키(Foreign Key)를 사용 |
| 자식 주식별자 영향 | 자식 주식별자의 구성에 포함됨 | 자식 일반 속성에 포함됨 |
| 표기법 | 실선으로 표현 | 점선으로 표 |
| 연결 고려사항 | - 반드시 부모엔터티 종속 - 자식 주식별자구성에 부모 주식별자포함 필요 - 상속받은 주식별자속성을 타 엔터티에 이전 필요 |
- 약한 종속관계 - 자식 주식별자구성을 독립적으로 구성 - 자식 주식별자구성에 부모 주식별자 부분 필요 - 상속받은 주식별자속성을 타 엔터티에 차단 필요 - 부모쪽의 관계참여가 선택관계 |
6. 정규화 과정
정규화란 데이터베이스 논리설계에서 효율적인 스키마를 만드는 작업이며
1 정규화부터 5 정규화까지 있지만 이를 순서대로 다 하지 않으며, 반정규화 같은 예외 상황도 존재합니다.
SQLD에서는 1~3 정규화와 반정규화까지 다룹니다.
1 정규화 (1NF)
테이블의 모든 속성(도메인)이 원자값을 지니는 상태로, 각 열을 더 나눌 수 없는 값이어야 함
조건
- 테이블의 모든 열은 원자값을 가져야 함
- 각 행은 고유해야 하며, 열의 순서는 무관함
-- 비정규화된 테이블
CREATE TABLE Orders (
OrderID INT,
CustomerName VARCHAR(100),
ProductIDs VARCHAR(100) -- "1,2,3" 같은 형태로 여러 값을 가짐
);
-- 1NF로 변환된 테이블
CREATE TABLE Orders (
OrderID INT,
CustomerName VARCHAR(100),
ProductID INT -- 1, 2, 3 으로 레코드마다 나뉘어진 상태
);
2 정규화 (2NF)
1 정규화를 지키면서 기본 키가 아닌 속성들이 기본 키에 완전 함수 종속인 상태
조건
- 1NF를 만족
- 기본 키의 일부가 아닌 모든 속성은 기본 키 전체에 종속적
-- 1NF를 만족하는 테이블
CREATE TABLE Orders (
OrderID INT,
ProductID INT,
CustomerName VARCHAR(100),
ProductName VARCHAR(100)
);
-- 2NF로 변환된 테이블, 2NF를 지키기 위해 테이블을 나눔
CREATE TABLE Orders (
OrderID INT,
ProductID INT,
PRIMARY KEY (OrderID, ProductID)
);
CREATE TABLE Products (
ProductID INT PRIMARY KEY,
ProductName VARCHAR(100)
);
CREATE TABLE Customers (
CustomerName VARCHAR(100) PRIMARY KEY
);
3 정규화 (3NF)
2NF를 만족하면서, 기본키를 제외한 속성들이 기본키에 이행적으로 종속이 아닌
직접적으로 종속되어야 함 (참고로 기본키 속성은 테이블에 하나만 있을 수 있음)
조건
- 2NF를 만족
- 기본 키가 아닌 모든 속성은 기본 키에 직접 종속적
-- 2NF를 만족하는 테이블
CREATE TABLE Orders (
OrderID INT,
ProductID INT,
CustomerID INT,
OrderDate DATE,
CustomerAddress VARCHAR(100) -- 이행적 종속성 존재 (CustomerID -> CustomerAddress)
);
-- 3NF로 변환된 테이블, 이행적 종속성이던 Customer를 따로 테이블로 분리함
CREATE TABLE Orders (
OrderID INT,
ProductID INT,
CustomerID INT,
OrderDate DATE,
PRIMARY KEY (OrderID)
);
CREATE TABLE Customers (
CustomerID INT PRIMARY KEY,
CustomerAddress VARCHAR(100)
);
반정규화
성능을 개선하기 위해 일부 정규화를 의도적으로 해제하는 과정입니다.
DB의 접근 속도를 높이고, 복잡한 조인을 줄일 수 있습니다
기법
- 중복 데이터 추가
- 테이블 병합
- 부분적 중복 허용
- 중복 인덱스 사용
- 계산된 컬럼 추가
7. 본질식별자 vs 인조식별자
본질식별자와 인조식별자는 엔티티의 인스턴스를 구분하기 위한 개념으로 각 식별자는 엔티티를 고유하게 하는 식별자 역할을 수행합니다.
본질식별자 (Natural Identifier)
엔티티 속성 중에서 그 데이터를 자연스럽게 대표하는 속성을 나타냅니다.
예를 들면
- 사람의 주민등록번호
- 자동차의 차량 번호
- 상품의 바코드 번호
인조식별자 (Artificial Identifier)
엔티티를 식별하기 위해 인위적으로 생성한 속성으로 DB 설계 과정에서 데이터의 고유성을 확보하기 위해 도입한 값으로 본질식별자를 정하기 애매하거나 존재하지 않을 경우 사용
예를 들면
- 사용자 고유 ID
- 트랜잭션 ID
- DB에서 자동으로 생성되는 일련번호 (auto_increment)
차이점
- 비즈니스 의존성: 본질식별자는 엔티티를 대표하는 속성을 사용하기 때문에 비즈니스 프로세스와 자연스럽게 강하게 연결 지을 수 있습니다, 인조식별자는 비즈니스 로직과는 독립적으로, 데이터 관리의 편의성을 위해 생성됩니다.
- 고유성: 본질식별자는 자연스러운 속성을 사용하므로 변경될 수 있거나 중복될 가능성이 있습니다. 인조식별자는 고유성이 보장되며 시스템 내에서 일관성을 유지하는 데 유리하며 중복되지 않습니다.
- 용도: 본질식별자는 비즈니스 로직을 반영하며 데이터의 식별 뿐만 아니라 의미 전달에도 중요한 역할을 합니다. 인조식별자는 주로 데이터베이스 내에서 데이터 무결성을 유지하는 데 중점을 둡니다.
참고로 데이터 모델링에서 적절한 식별자를 찾는 것은 데이터의 일관성, 무결설, 접근성을 보장하는데 중요합니다.
8. 엔티티 관계
기본 정보
- 엔터티(Entity): 관리하려는 데이터의 실체, 테이블로 구현됩니다.
- 속성(Attribute): 엔터티의 특성, 테이블의 컬럼으로 구현됩니다.
- 관계(Relationship): 엔터티 간의 연관성을 나타내며, 주로 외래 키(Foreign Key)를 통해 구현됩니다.
관계 유형
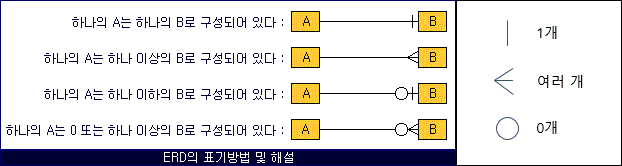
유형 일대일 관계 (1:1): 한 엔터티의 각 인스턴스가 다른 엔터티의 하나의 인스턴스와 연결. 일대다 관계 (1:N): 한 엔터티의 각 인스턴스가 다른 엔터티의 여러 인스턴스와 연결. 다대다 관계 (N:N): 한 엔터티의 각 인스턴스가 다른 엔터티의 여러 인스턴스와 상호 연결, 보통 연관 엔터티를 통해 해결.
SQLD 2과목, SQL 기본 및 활용
1. 관계형 데이터베이스 개요
데이터를 테이블(table) 형태로 구조화하여 관리하는 데이터베이스 시스템입니다. 각 테이블은 행(row)과 열(column)로 구성되며, 데이터는 행 단위로 저장됩니다. 열은 각각 특정 데이터 타입을 가지며, 테이블 간의 관계는 키(key)를 통해 정의됩니다.
RDB의 특징
- 데이터 무결성
- 데이터의 정확성과 일관성을 유지하기 위한 다양한 무결성 제약 조건을 지원함
- 예를 들어, 기본 키 제약, 외래 키 제약, 고유 제약이 존재
- SQL
- SQL을 사용하여 데이터를 정의(DDL), 조작(DML), 제어(DCL)를 합니다.
- 데이터 독립성
- 관계형 데이터베이스는 물리적 저장 구조와 논리적 데이터 구조를 분리하여 데이터 독립성을 제공
- 이로 인해 DB의 구조 변경은 애플리케이션에 미치는 영향을 최소화함
- 트랜잭션 관리
- RDB는 트랜잭션을 통해 데이터의 일관성 및 무결성을 보장
- 트랜잭션은 원자성, 일관성, 고립성, 지속성의 특성을 충족해야 함
- 원자성 (Atomicity): 트랜잭션의 모든 작업이 완료되거나 전혀 수행되지 않음을 보장.
- 일관성 (Consistency): 트랜잭션이 완료된 후에도 데이터베이스가 일관된 상태를 유지하도록 보장.
- 고립성 (Isolation): 동시 실행되는 트랜잭션들이 서로 영향을 주지 못하도록 보장.
- 지속성 (Durability): 트랜잭션이 완료된 후에는 시스템 오류가 발생하더라도 그 결과가 데이터베이스에 영구적으로 반영됨을 보장.
2. 절차적, 비절차적 데이터 조작어
절차적 데이터 조작어 (Procedural DML)
DB 내에서 데이터를 조작하는 방법을 세밀하게 정의하는 방법으로, 사용자 원하는 결과를 얻기 위해 어떻게 데이터를 처리할지를 명확하게 지정함
특징으론 세부적인 제어, 복잡한 논리 처리, 루프 및 조건문 사용등이 있다
아래는 예시로 대표적인 절차적 SQL은 PL/SQL, T-SQL 등이 있다.
DECLARE
v_employee_id NUMBER;
BEGIN
FOR v_employee_id IN (SELECT employee_id FROM employees WHERE department_id = 10) LOOP
UPDATE employees SET salary = salary * 1.1 WHERE employee_id = v_employee_id;
END LOOP;
END;
비절차적 데이터 조작어 (Non-Procedural DML)
사용자는 원하는 결과만 정하고 나머지는 DBMS에서 알아서 해주는 방식으로 더 간결하고 고수준의 추상화를 제공하며
DBMS가 알아서 최적화된 방식으로 작업을 수행해 줌
예시로는 SQL이 있다.
3. 조인(Join)
아래 테이블을 기준으로 예시를 진행하겠습니다.
Emplyees 테이블
| employee_id | employee_name | department_id |
| 1 | Alice | 10 |
| 2 | Bob | 20 |
| 3 | Charlie | NULL |
| 4 | David | 30 |
Departments 테이블
| department_id | department_name |
| 10 | HR |
| 20 | IT |
| 30 | Marketing |
| 40 | Sales |
INNER JOIN: 두 테이블에서 일치하는 레코드만 반환.
SELECT e.employee_id, e.employee_name, d.department_name
FROM employees e
INNER JOIN departments d
ON e.department_id = d.department_id;| employee_id |
employee_name | department_name |
| 1 | Alice | HR |
| 2 | Bob | IT |
| 4 | David | Marketing |
LEFT OUTER JOIN: 왼쪽 테이블의 모든 레코드와 오른쪽 테이블의 일치하는 레코드 반환.
SELECT e.employee_id, e.employee_name, d.department_name
FROM employees e
LEFT OUTER JOIN departments d
ON e.department_id = d.department_id;| employee_id | employee_name | department_name |
| 1 | Alice | HR |
| 2 | Bob | IT |
| 3 | Charlie | NULL |
| 4 | David | Marketing |
RIGHT OUTER JOIN: 오른쪽 테이블의 모든 레코드와 왼쪽 테이블의 일치하는 레코드 반환.
SELECT e.employee_id, e.employee_name, d.department_name
FROM employees e
RIGHT OUTER JOIN departments d
ON e.department_id = d.department_id;| employee_id | employee_name | department_name |
| 1 | Alice | HR |
| 2 | Bob | IT |
| 4 | David | Marketing |
| NULL | NULL | Sales |
FULL OUTER JOIN: 두 테이블의 모든 레코드를 반환하며, 일치하지 않는 경우 NULL로 채움.
SELECT e.employee_id, e.employee_name, d.department_name
FROM employees e
FULL OUTER JOIN departments d
ON e.department_id = d.department_id;| employee_id | employee_name | department_name |
| 1 | Alice | HR |
| 2 | Bob | IT |
| 3 | Charlie | NULL |
| 4 | David | Marketing |
| NULL | NULL | Sales |
CROSS JOIN: 두 테이블의 모든 가능한 조합을 반환.
SELECT e.employee_id, e.employee_name, d.department_name
FROM employees e
CROSS JOIN departments d;| employee_id | employee_name | department_name |
| 1 | Alice | HR |
| 1 | Alice | IT |
| 1 | Alice | Marketing |
| 1 | Alice | Sales |
| 2 | Bob | HR |
| 2 | Bob | IT |
| 3 | Bob | Marketing |
| 2 | Bob | Sales |
| 3 | Charlie | HR |
| ... | ... | ... |
SELF JOIN: 동일한 테이블을 두 번 참조하여 조인.
SELECT e1.employee_id, e1.employee_name, e2.employee_name AS manager_name
FROM employees e1
INNER JOIN employees e2
ON e1.department_id = e2.department_id;| employee_id | employee_name | department_name |
| 1 | Alice | Alice |
| 2 | Bob | Bob |
| 4 | David | David |
NATURAL JOIN: 이름과 타입을 기준으로 모든 컬럼을 자동 조인
SELECT *
FROM eployees
NATURAL JOIN departments;| employee_id | employee_name | department_id | department_name |
| 1 | Alice | 10 | HR |
| 2 | Bob | 20 | IT |
| 4 | David | 30 | Marketing |
USING
조인할 컬럼을 지정합니다. 컬럼명은 같아야 합니다.
SELECT *
FROM Orders
JOIN Customers
USING (CustomerID);ON
조인할 컬럼을 지정하지만 컬럼명이 달라도 됩니다.
SELECT *
FROM Orders
JOIN Customers
ON Orders.CustomerID = Customers.ID;
4. NULL 관련 함수(DBMS에 따라 사용법이 살짝 다름)
- NVL: 첫 번째 인수가 NULL이면 두 번째 인수를 반환 (Oracle).
- NVL(expr1, expr2)
- expr1: 검사할 표현식.
- expr2: expr1이 NULL일 때 반환할 값.
- COALESCE: 인수 리스트에서 첫 번째로 NULL이 아닌 값을 반환.
- COALESCE(expr1, expr2, ..., exprn)
- expr1, expr2, ..., exprn: 검사할 표현식의 리스트.
- NULLIF: 두 인수가 같으면 NULL을 반환, 그렇지 않으면 첫 번째 인수를 반환.
- NULLIF(expr1, expr2)
- expr1: 첫 번째 표현식, expr2: 두 번째 표현식.
- CASE: 조건에 따라 다양한 값을 반환.
CASE
WHEN condition1 THEN result1
WHEN condition2 THEN result2
...
ELSE resultN
END
-- 예제 --
SELECT
CASE
WHEN salary IS NOT NULL THEN salary
ELSE 'Salary not available'
END AS salary_status
FROM employees;- ISNULL: 첫 번째 인수가 NULL이면 두 번째 인수를 반환 (SQL Server).
- ISNULL(expr1, expr2)
- expr1: 검사할 표현식, expr2: expr1이 NULL일 때 반환할 값.
- IFNULL: 첫 번째 인수가 NULL이면 두 번째 인수를 반환 (MySQL).
- IFNULL(expr1, expr2)
- expr1: 검사할 표현식. expr2: expr1이 NULL일 때 반환할 값.
5. PRIOR 키워드
PRIOR 키워드는 계층적 쿼리에서 주로 부모-자식 관계를 나타내기 위해 사용됩니다.
이를 통해 트리 구조의 데이터에서 부모와 자식 노드를 식별할 수 있습니다.
이걸 통해 계층질의에 역방향, 순방향을 정할 수 있습니다.
기본문법
SELECT column_list
FROM table_name
START WITH condition
CONNECT BY PRIOR parent_column = child_column;- START WITH: 계층적 쿼리의 시작점을 지정
- CONNECT BY: 부모-자식 관계를 정의
- PRIOR: 부모와 자식 간의 관계를 나타냄
다음같은 테이블이 있을 때
| employee_id | employee_name | manager_id |
| 1 | Alice | NULL |
| 2 | Bob | 1 |
| 3 | Charile | 1 |
| 4 | David | 2 |
| 5 | Eve | 2 |
이를 아래 쿼리로 실행하면
SELECT employee_id, employee_name, manager_id, LEVEL
FROM employees
START WITH manager_id IS NULL
CONNECT BY PRIOR employee_id = manager_id;결과
| employee_id | employee_name | manager_id | LEVEL |
| 1 | Alice | NULL | 1 |
| 2 | Bob | 1 | 2 |
| 3 | Charile | 1 | 2 |
| 4 | David | 2 | 3 |
| 5 | Eve | 2 | 3 |
위에서 사용한 LEVEL 키워드는 현재 노드의 깊이를 나타내는 가상 컬럼으로 루트 노드는 LEVEL 1, 자식 노드는 부모 노드의 LEVEL + 1 값을 가짐.
SYS_CONNECT_BY_PATH
계층적 쿼리에서 루트 노드부터 현재 노드까지의 경로를 문자열로 반환
SELECT employee_id, employee_name, SYS_CONNECT_BY_PATH(employee_name, '->') AS path
FROM employees
START WITH manager_id IS NULL
CONNECT BY PRIOR employee_id = manager_id;
결과
| employee_id | employee_name | path |
| 1 | Alice | ->Alice |
| 2 | Bob | ->Alice->Bob |
| 3 | Charile | ->Alice->Charlie |
| 4 | David | ->Alice->Bob->David |
| 5 | Eve | ->Alice->Bob->Eve |
CONNECT_BY_ISLEAF
CONNECT_BY_ISLEAF 가상 컬럼은 현재 노드가 리프 노드(자식이 없는 노드)인지 여부를 나타냅니다.
리프 노드면 1을, 그렇지 않으면 0을 반환
SELECT employee_id, employee_name, CONNECT_BY_ISLEAF AS is_leaf
FROM employees
START WITH manager_id IS NULL
CONNECT BY PRIOR employee_id = manager_id;
결과
| employee_id | employee_name | pathis_leaf |
| 1 | Alice | 0 |
| 2 | Bob | 0 |
| 3 | Charile | 1 |
| 4 | David | 1 |
| 5 | Eve | 1 |
6. 서브쿼리
SQL에서 하나의 쿼리 내에 포함된 또 다른 쿼리를 의미하며 서브쿼리는 주로 SELECT, INSERT, UPDATE, DELETE 문 내에서 사용되어 복잡한 데이터 검색이나 데이터 처리에 사용됩니다.
크게 2가지 유형으로 나눌 수 있습니다.
단일 행 서브쿼리 (Single-row Subquery)
하나의 행만 반환하는 서브쿼리로 보통 =, <, >, <=, >=, <> 등의 연산자와 함께 사용
SELECT employee_id, employee_name
FROM employees
WHERE department_id = (SELECT department_id FROM departments WHERE department_name = 'IT');
다중 행 서브쿼리 (Multi-row Subquery)
여러 행을 반환할 수 있는 서브쿼리로 IN, ANY, ALL, EXISTS 등의 연산자와 함께 사용됩니다.
SELECT employee_id, employee_name
FROM employees
WHERE department_id IN (SELECT department_id FROM departments WHERE location_id = 1700);
이를 요약하면
- 단일 행 서브쿼리: 하나의 행을 반환.
- 다중 행 서브쿼리: 여러 행을 반환.
- SELECT 절의 서브쿼리: 계산된 컬럼 생성.
- FROM 절의 서브쿼리: 인라인 뷰 또는 임시 테이블.
- WHERE 절의 서브쿼리: 조건 필터링.
- HAVING 절의 서브쿼리: 그룹화된 결과 집합 필터링.
- 상관 서브쿼리: 외부 쿼리의 각 행에 대해 실행.
7. 순위 매기기
RANK
RANK 함수는 순위를 매길 때 동점이 있는 경우 동일한 순위를 부여하고 다음 순위를 건너뜀
문법
RANK() OVER ([PARTITION BY column_list] ORDER BY column_list)예제
SELECT employee_id, employee_name, salary,
RANK() OVER (ORDER BY salary DESC) AS rank
FROM employees;| employee_id | employee_name | salary | rank |
| 6 | Frank | 8000 | 1 |
| 2 | Bob | 7000 | 2 |
| 3 | Charlie | 7000 | 2 |
| 4 | David | 6000 | 4 |
| 5 | Eve | 6000 | 4 |
| 1 | Alice | 5000 | 6 |
여기서 rank를 적용하는 계층을 PARTITION BY로 나눠서 랭크를 적용할 수 있습니다.
PARTITION BY는 나머지 DENSE_RANK, ROW_NUMBER에도 적용할 수 있습니다
SELECT employee_id, employee_name, department_id, salary,
RANK() OVER (PARTITION BY department_id ORDER BY salary DESC) AS dept_rank
FROM employees;| employee_id | employee_name | department_id | salary | rank |
| 2 | Bob | 10 | 7000 | 1 |
| 3 | Charlie | 10 | 7000 | 1 |
| 1 | Alice | 10 | 5000 | 3 |
| 6 | Frank | 20 | 8000 | 1 |
| 4 | David | 20 | 6000 | 2 |
| 5 | Eve | 20 | 6000 | 2 |
DENSE_RANK
RANK처럼 DENSE_RANK 함수는 순위를 매길 때 동점이 있는 경우 동일한 순위를 부여하지만,
RANK와 다르게 다음 순위를 건너뛰지 않습니다.
문법
DENSE_RANK() OVER ([PARTITION BY column_list] ORDER BY column_list)예제
SELECT employee_id, employee_name, salary,
DENSE_RANK() OVER (ORDER BY salary DESC) AS dense_rank
FROM employees;| employee_id | employee_name | salary | dense_rank |
| 6 | Frank | 8000 | 1 |
| 2 | Bob | 7000 | 2 |
| 3 | Charlie | 7000 | 2 |
| 4 | David | 6000 | 3 |
| 5 | Eve | 6000 | 3 |
| 1 | Alice | 5000 | 4 |
ROW_NUMBER
ROW_NUMBER 함수는 행 번호를 매기며 동점이 발생해도 고유한 순번이 매겨집니다.
문법
ROW_NUMBER() OVER ([PARTITION BY column_list] ORDER BY column_list)예제
SELECT employee_id, employee_name, salary,
ROW_NUMBER() OVER (ORDER BY salary DESC) AS row_num
FROM employees;| employee_id | employee_name | salary | dense_rank |
| 6 | Frank | 8000 | 1 |
| 2 | Bob | 7000 | 2 |
| 3 | Charlie | 7000 | 3 |
| 4 | David | 6000 | 4 |
| 5 | Eve | 6000 | 5 |
| 1 | Alice | 5000 | 6 |
요약
- RANK(): 동일한 값에 동일한 순위를 부여하고 다음 순위를 건너뜀
- DENSE_RANK(): 동일한 값에 동일한 순위를 부여하지만, 다음 순위를 건너뛰지 않음
- ROW_NUMBER(): 모든 행에 고유한 순위를 부여
- PARTITION BY: 데이터를 파티션으로 나누어 각 파티션 내에서 별도로 순위 부여
8. 차집합, 합집합, 교집합
차집합
두 개의 테이블에서 하나의 집합에만 존재하는 요소를 찾을 때 사용됩니다
DBMS마다 키워드는 다릅니다
- EXCEPT : 주로 Microsoft SQL Server, PostgreSQL에서 사용
- MINUS: 주로 Oracle에서 사용
아래 테이블을 예시로 하면
employees_2023 Table
| employee_id | employee_name |
| 1 | Alice |
| 2 | Bob |
| 3 | Charlie |
| 4 | David |
employees_2024 Table
| employee_id | employee_name |
| 3 | Charlie |
| 4 | David |
| 5 | Eva |
| 6 | Frank |
예제
아래 두 SQL은 같은 결과를 보여줍니다
SELECT employee_id, employee_name
FROM employees_2023
EXCEPT
SELECT employee_id, employee_name
FROM employees_2024;
------ 위와 아래는 동일 ------
SELECT employee_id, employee_name
FROM employees_2023
MINUS
SELECT employee_id, employee_name
FROM employees_2024;| employee_id | employee_name |
| 1 | Alice |
| 2 | Bob |
차집합 사용할 때의 주의사항
- 컬럼의 수와 데이터 타입 일치: 두 쿼리에서 반환되는 컬럼의 수와 데이터 타입이 동일해야 함
- 순서: 첫 번째 쿼리의 결과에서 두 번째 쿼리의 결과를 제외하므로 순서가 중요
- NULL 값: NULL 값도 비교 대상에 포함되므로, NULL 값 처리에 주의
합집합
UNION: 두 쿼리의 결과를 합집합으로 반환하며 기본적으로 중복을 제거하며 UNION ALL로 하면 중복도 포함됩니다
SELECT employee_id, employee_name
FROM employees_2023
UNION
SELECT employee_id, employee_name
FROM employees_2024;
교집합
ITERSECT: 두 개의 SELECT 문의 결과 집합에서 공통으로 존재하는 행을 반환합니다. 교집합 연산을 통해 두 테이블 간의 공통된 데이터를 쉽게 찾을 수 있음, SELECT로 꺼낸 컬럼이 모두 동일해야 됨
SELECT employee_id, employee_name
FROM employees_2023
INTERSECT
SELECT employee_id, employee_name
FROM employees_2024;
9. SELECT 논리적 실행 순서
FROM -> JOIN -> WHERE -> GROUP BY -> HAVING -> SELECT -> DISTINCT -> ODER BY -> LIMT/OFFSET
위 특징 때문에 아래 두 쿼리는 전혀 다른 결과를 나타냄이유는 ROWNUM에 경우 SELECT 절로 먼저 값을 매긴 다음 ORDER BY가 적용되기 때문
--- 정상적으로 상위 5명이 출력
SELECT * FROM (SELECT EMPNO, ENAME, DEPTNO, SAL,
RANK() OVER(ORDER BY SAL DESC) AS SAL_RANK FROM EMP) WHERE SAL_RANK <=5
--- SELECT에 윈도우 함수보(ROWNUM)보다 ORDER BY가 늦게 실행되므로 상위 5명을 올바르게 가져오지 못함
SELECT * FROM (SELECT E.*, ROWNUM AS SAL_RANK FROM EMP E ORDER BY SAL DESC) WHERE SAL_RANK <=5;
10. Having
GROUP BY 절에 의해 생성된 그룹의 결과에 조건을 적용하는 데 사용되어 특정 조건을 만족하는 그룹만을 결과로 반환하게 합니다. 이 절은 WHERE 절과 유사하게 조건을 제공하지만, 주요 차이점은 HAVING은 그룹화된 결과에 대한 조건을, WHERE는 개별 행에 대한 조건을 적용한다는 것입니다.
SELECT department, COUNT(*) AS num_employees
FROM employees
GROUP BY department
HAVING COUNT(*) > 10;
11. 카테시안 곱
두 개 이상의 테이블에서 모든 가능한 행 조합을 생성되는 것
대부분의 경우 원하지 않는 결과와 성능 저하를 초래합니다. 하지만 특정 상황에서 의도적으로 사용되기도 함
A의 각 행이 B의 각 행과 결합되는 걸로 A가 3개의행 B가 4개의 있을 경우 결과 집합은 3x2=12이다
SELECT *
FROM Employees, Departments;
12. 테이블 생성 후 복제 (CTAS) 제약조건
CTAS의 기본 작동 방식
CTAS는 주로 데이터 구조를 빠르게 복제하고 선택적으로 데이터를 필터링하여 새 테이블을 만들 때 사용됩니다.
제약조건
CTAS로 생성된 테이블은 기존 테이블의 데이터는 포함하지만, 다음과 같은 객체는 포함하지 않음
- Primary Keys
- Foreign Keys
- Unique Constraints
- Indexes
- Triggers
- Stored Procedures and Functions (테이블과 직접 연결된 것이 아닌 경우
새 테이블에 제약조건을 추가하려면 ALTER TABLE로 추가해야 함
사용 시 고려사항
- 데이터 복제의 목적: CTAS는 데이터 마이그레이션, 백업, 테스트 환경 구축 등 다양한 상황에서 유용합니다. 하지만 이때 데이터 무결성과 관련된 모든 제약조건을 수동으로 관리해야 합니다.
- 성능 문제: 인덱스나 제약조건이 없는 테이블은 특정 쿼리에서 성능 저하를 일으킬 수 있습니다. 따라서, 운영 환경에서 사용하기 전에는 적절한 인덱스를 추가하고 최적화하는 것이 중요합니다.
- 데이터 무결성 유지: 완전한 데이터 무결성을 유지하기 위해서는 기존 테이블에서 사용하던 제약조건을 새 테이블에도 적용해야 합니다.
13. SQL 특성
- 구조적(Structured): 표준화된 문법을 사용하여 데이터를 체계적으로 관리하고 조작
- 집합적(Set-based): 데이터를 개별적으로 처리하는 대신 집합으로 다루며, 대량의 데이터를 효율적으로 처리할 수 있게 함
- 선언적(Declarative): 사용자는 결과를 얻기 위해 필요한 작업을 세세하게 지정하지 않고 원하는 결과만을 선언
- 비절차적(Non-procedural): 데이터를 어떻게 처리할지는 DBMS에 맡기고, 사용자는 원하는 결과의 조건만을 명시
14. Rollup
GROUP BY 절과 함께 사용되어 하위 집계 레벨로부터 요약된 결과를 단계별로 제공하며, 부분합과 총합을 계산하는 데 사용합니다, 말로는 설명하기 어려운 기능입니다.
아래는 Year, Month, Day를 기준으로 부분합 총합을 구하는 예제입니다.
Null은 전부를 포함합니다.
예제
| Year | Month | Day | SalesAmount |
| 2023 | 1 | 1 | 100 |
| 2023 | 1 | 2 | 150 |
| 2023 | 2 | 1 | 200 |
| 2024 | 1 | 1 | 120 |
| 2024 | 1 | 2 | 180 |
SELECT Year, Month, Day, SUM(SalesAmount) AS TotalSales
FROM Sales
GROUP BY ROLLUP(Year, Month, Day);| Year | Month | Day | TotalSales |
| 2023 | 1 | 1 | 100 |
| 2023 | 1 | 2 | 150 |
| 2023 | 1 | NULL | 250 |
| 2023 | 2 | 1 | 200 |
| 2023 | 2 | NULL | 200 |
| 2023 | NULL | NULL | 450 |
| 2024 | 1 | 1 | 120 |
| 2024 | 1 | 2 | 180 |
| 2024 | 1 | NULL | 300 |
| 2024 | NULL | NULL | 300 |
| NULL | NULL | NULL | 750 |
결과 분석
- 일별 합계: 각 일자별로 SalesAmount의 합계를 보여줍니다.
- 월별 합계: 각 월별로 모든 일자의 SalesAmount 합계를 보여줍니다 (예: 2023년 1월의 총판매 합계는 250입니다).
- 연도별 합계: 각 연도별로 모든 월의 SalesAmount 합계를 보여줍니다 (예: 2023년의 총판매 합계는 450입니다).
- 전체 합계(마지막 row): 테이블 전체(NULL 3개인 경우)에 대한 SalesAmount의 총합계입니다.
15. Check, Default
Check와 Default는 테이블 정의 시 사용되는 제약조건으로 데이터를 입력하거나 수정할 때 무결설을 유지하는데 도움을 줍니다.
Check
데이터가 입력되거나 수정될 때 확인되는 조건 지정
CREATE TABLE Employees (
ID INT,
Age INT,
Salary DECIMAL(10, 2),
CHECK (Age >= 18) -- 직원의 나이가 18세 이상이어야 한다는 조건
);
Default
데이터가 없을 때의 기본 값 지정
CREATE TABLE Employees (
ID INT,
Name VARCHAR(100),
Department VARCHAR(50) DEFAULT 'General' -- 기본적으로 'General' 부서에 속하도록 설정
);
16. CUBE
CUBE는 GROUP BY 절과 함께 사용됩니다.
예를 들어, 어떤 회사의 판매 데이터가 있을 때, 제품, 지역, 시간 등 다양한 차원에서 판매 합계를 보고 싶다면
CUBE를 사용할 수 있습니다.
Sales Table
| Product | Region | SaleDate | SalesAmount |
| A | North | 2023-01-01 | 100 |
| A | South | 2023-01-01 | 150 |
| B | North | 2023-01-01 | 200 |
| B | South | 2023-01-01 | 250 |
예제 SQL
SELECT Product, Region, SUM(SalesAmount)
FROM Sales
GROUP BY CUBE (Product, Region);결과
| Product | Region | SUM(SalesAmount) |
|---------|--------|------------------|
| A | North | 100 |
| A | South | 150 |
| B | North | 200 |
| B | South | 250 |
| A | NULL | 250 | -- A의 모든 지역 합계
| B | NULL | 450 | -- B의 모든 지역 합계
| NULL | North | 300 | -- 모든 제품의 북부 지역 합계
| NULL | South | 400 | -- 모든 제품의 남부 지역 합계
| NULL | NULL | 700 | -- 전체 합계
ROLLUP은
계층적으로 서브토탈을 생성하는 데 사용되며 "순차적" 차원을 갖는 집계에 유용하며, 주어진 목록의 순서대로 서브토탈을 계산합니다.
CUBE는
지정된 모든 차원의 가능한 모든 조합을 포함한 결과를 생성합니다. 이는 데이터를 다차원적으로 분석할 때 유용하며, 모든 가능한 서브토탈과 총계를 계산합니다.
비유로 설명하면
ROLLUP은 책의 목차를 정하듯 큰 주제에서부터 작은 주제로 나열하며
CUBE는 큐브 퍼즐을 맞추듯 모든 조합을 고려해서 여러 방향으로 데이터를 살펴봅니다
17. MERGE
UPSERT라고도 불리며 이는 데이터베이스에서 기존 행을 업데이트하거나, 존재하지 않을 경우 새로운 행을 삽입하는 작업을 하나의 연산으로 수행할 수 있게 해 줍니다. 이 명령은 주로 데이터 동기화 작업에 사용되며, 복잡한 로직 없이 데이터를 최신 상태로 유지할 수 있도록 돕습니다.
문법
MERGE INTO target_table USING source_table
ON (merge_condition)
WHEN MATCHED THEN
UPDATE SET column1 = value1, column2 = value2, ...
WHEN NOT MATCHED THEN
INSERT (column1, column2, ...) VALUES (value1, value2, ...);- TARGET_TABLE: 데이터를 업데이트하거나 삽입할 대상 테이블입니다.
- SOURCE_TABLE: 대상 테이블과 비교할 소스 데이터(테이블, 뷰, 또는 다른 SQL 쿼리 결과)입니다.
- MERGE_CONDITION: 두 테이블을 어떻게 비교할 것인지 정의합니다. 일반적으로 키 또는 고유 식별자를 사용합니다.
- WHEN MATCHED: MERGE_CONDITION을 만족하는 즉, 매치되는 행이 있을 경우 수행할 작업을 정의합니다. 주로 특정 컬럼을 업데이트합니다.
- WHEN NOT MATCHED: 매치되는 행이 없을 경우 수행할 작업을 정의합니다. 주로 새로운 행을 삽입합니다.
즉 target_table에 값을 넣을 때 source_table와 함께 merge_condition을 체크 후 로직을 정할 수 있습니다.
UPSERT라는 다른 이름처럼 UPDATE + INSERT 느낌입니다.
18. 날짜 함수
1. 현재 시간
- CURRENT_DATE: 현재 날짜를 반환합니다.
- CURRENT_TIME: 현재 시간을 반환합니다.
- CURRENT_TIMESTAMP: 현재 날짜와 시간을 반환합니다.
SELECT CURRENT_DATE, CURRENT_TIME, CURRENT_TIMESTAMP;
2. 특정 영역 추출
--- DATE_PART (PostgreSQL)
SELECT EXTRACT(YEAR FROM '2024-05-13');
SELECT EXTRACT(MONTH FROM '2024-05-13');
SELECT EXTRACT(DAY FROM '2024-05-13');
--- DATE_PART (PostgreSQL)
SELECT DATE_PART('year', TIMESTAMP '2024-05-13');
SELECT DATE_PART('month', TIMESTAMP '2024-05-13');
SELECT DATE_PART('day', TIMESTAMP '2024-05-13');
3. 날짜 계산
SELECT DATE_ADD('2024-05-13', INTERVAL 10 DAY);
SELECT DATE_SUB('2024-05-13', INTERVAL 5 DAY);
SELECT DATEDIFF(day, '2024-01-01', '2024-05-13');
4. 문자열을 날짜로
--- PostgreSQL
SELECT TO_DATE('2024-05-13', 'YYYY-MM-DD');
--- MySQL
SELECT STR_TO_DATE('2024-05-13', '%Y-%m-%d');
5. 날짜 포맷
--- MsSQL
SELECT DATE_FORMAT(CURRENT_DATE, '%Y-%m-%d');
--- PostgreSQL
SELECT TO_CHAR(CURRENT_DATE, 'YYYY-MM-DD');
19. PIVOT, UNPIVOT
PIVOT : 데이터 행을 열로 변환하여 요약된 데이터를 만들 때 사용되며, 이는 주로 데이터 요약과 보고서를 만들 때 이용
UNPIVOT : 열을 행으로 변환하여 데이터의 세부 정보를 복원할 때 사용되며, 이는 주로 데이터 정규화와 상세 분석에 이용
만약 숫자로 된 컬럼을 가리킬 경우 ''로 감싸면 됨
다음 Sales 테이블을 기준으로 예시를 들면
| Year | Quarter | SalesAmount |
| 2023 | Q1 | 1000 |
| 2023 | Q2 | 1500 |
| 2023 | Q3 | 2000 |
| 2023 | Q4 | 2500 |
| 2024 | Q1 | 1100 |
| 2024 | Q2 | 1600 |
| 2024 | Q3 | 2100 |
| 2024 | Q4 | 2600 |
PIVOT 예제
SELECT Year,
[Q1] AS Q1_Sales,
[Q2] AS Q2_Sales,
[Q3] AS Q3_Sales,
[Q4] AS Q4_Sales
FROM
(
SELECT Year, Quarter, SalesAmount
FROM Sales
) AS SourceTable
PIVOT
(
SUM(SalesAmount)
FOR Quarter IN ([Q1], [Q2], [Q3], [Q4])
) AS PivotTable;| Year | Q1_Sales | Q2_Sales | Q3_Sales | Q4_Sales |
| 2023 | 1000 | 1500 | 2000 | 2500 |
| 2024 | 1100 | 1600 | 2100 | 2600 |
참고로 기준 값은 FROM 안에 SELECT 절에서 가져온 값 중 사용되지 않은 값이 됨
UNPIVOT 예제
PIVOT으로 생성한 테이블을 다시 열을 행으로 바꾸는데 이용합니다.
SELECT Year, Quarter, SalesAmount
FROM
(
SELECT Year, Q1_Sales, Q2_Sales, Q3_Sales, Q4_Sales
FROM PivotTable
) AS PivotedTable
UNPIVOT
(
SalesAmount FOR Quarter IN (Q1_Sales, Q2_Sales, Q3_Sales, Q4_Sales)
) AS UnpivotedTable;| Year | Quarter | SalesAmount |
| 2023 | Q1_Sales | 1000 |
| 2023 | Q2_Sales | 1500 |
| 2023 | Q3_Sales | 2000 |
| 2023 | Q4_Sales | 2500 |
| 2024 | Q1_Sales | 1100 |
| 2024 | Q2_Sales | 1600 |
| 2024 | Q3_Sales | 2100 |
| 2024 | Q4_Sales | 2600 |
20. 정규표현식
정규 표현식(Regular Expression)은 패턴 매칭을 통해 문자열을 검색하고 조작하는 강력한 도구로 정규 표현식은 특정한 문자열 패턴을 정의하고, 해당 패턴과 일치하는 문자열을 찾거나 변형하는 데 사용됩니다.
MySQL
REGEXP 연산자를 사용하여 정규 표현식을 이용한 패턴 매칭을 수행 (아래 정규식은 이메일)
SELECT * FROM users
WHERE email REGEXP '^[a-zA-Z0-9._%+-]+@[a-zA-Z0-9.-]+\.[a-zA-Z]{2,}$';
PostgreSQL
~ 연산자를 사용하여 정규 표현식을 이용한 패턴 매칭을 수행 (아래 정규식은 이메일)
SELECT * FROM users
WHERE email ~ '^[a-zA-Z0-9._%+-]+@[a-zA-Z0-9.-]+\.[a-zA-Z]{2,}$';
정규 표현식의 기본 구성 요소
- 문자 클래스: [abc]는 'a', 'b', 'c' 중 하나와 일치
- 범위: [a-z]는 소문자 알파벳 문자와 일치
- 반대: [^abc]는 'a', 'b', 'c'가 아닌 문자와 일치
- 문자열 시작: ^는 문자열의 시작을 표현
- 문자열 끝: $는 문자열의 끝을 표현
- 임의의 문자: .는 임의의 한 문자와 일치
- 반복: * (0회 이상), + (1회 이상), ? (0 또는 1회), {n} (정확히 n회), {n,} (n회 이상), {n,m} (n회 이상 m회 이하) 반복을 함
21. LAG, LEAD
LAG 함수는 현재 행보다 지정된 오프셋(이전 행)만큼 뒤에 있는 행의 값을 반환합니다.
기본적으로 이전 행의 값을 가져오지만, 오프셋을 거리를 조정할 수 있습니다.
즉 LAG 자체의 의미 지연시킨다는 의미로 사용할 수 있습니다.
LAG(column_name, offset, default_value) OVER (PARTITION BY partition_column ORDER BY order_column)- column_name: 이전 값을 가져올 열.
- offset: 몇 행 이전의 값을 가져올지 지정 (기본값은 1).
- default_value: 이전 행이 존재하지 않을 때 반환할 기본값 (선택 사항).
- PARTITION BY: 파티션을 나누는 기준 (선택 사항). ORDER BY: 행을 정렬하는 기준.
아래처럼 직원을 기준으로 이전 직원과의 급여를 비교할 수 도 있습니다.
SELECT
employee_id,
employee_name,
salary,
LAG(salary, 1, 0) OVER (ORDER BY employee_id) AS previous_salary
FROM employees;| employee_id | employee_name | salary | previous_salary |
| 1 | Alice | 50000 | 0 |
| 2 | Bob | 60000 | 50000 |
| 3 | Charlie | 55000 | 60000 |
| 4 | David | 70000 | 55000 |
| 5 | Eve | 80000 | 70000 |
LEAD 함수는 현재 행보다 지정된 오프셋(다음 행)만큼 앞에 있는 행의 값을 반환합니다.
기본적으로 다음 행의 값을 가져오지만, 오프셋을 조정할 수 있습니다.
LAG와 반대의 쓰임을 지닙니다.
LEAD(column_name, offset, default_value) OVER (PARTITION BY partition_column ORDER BY order_column)- column_name: 다음 값을 가져올 열.
- offset: 몇 행 이후의 값을 가져올지 지정 (기본값은 1).
- default_value: 다음 행이 존재하지 않을 때 반환할 기본값 (선택 사항).
- PARTITION BY: 파티션을 나누는 기준 (선택 사항).
- ORDER BY: 행을 정렬하는 기준.
이번에는 다음 직원과의 비교를 할 수 있습니다.
SELECT
employee_id,
employee_name,
salary,
LEAD(salary, 1, 0) OVER (ORDER BY employee_id) AS next_salary
FROM employees;| employee_id | employee_name | salary | next_salary |
| 1 | Alice | 50000 | 60000 |
| 2 | Bob | 60000 | 55000 |
| 3 | Charlie | 55000 | 70000 |
| 4 | David | 70000 | 80000 |
| 5 | Eve | 80000 | 0 |
22. Auto Commit
Oracle
- 기본으로 Auto Commit이 비활성화
- Auto Commit을 꺼도 DDL은 자동 Commit은 됨
- DML 실행 시 자동으로 TRANSACTION 실행되며 이를 COMMIT , ROLLBACK으로 관리
SQL Server
- 기본으로 Auto Commit 활성
- Auto Commit을 끄면 BEGIN TRANSACTION 및 COMMIT, ROLLBACK을 해야 함
공통점
- Auto Commit 활성화 시 SQL문에 자동 Commit
- Auto Commit을 끄면 자동 Commit을 하지 않음
| 암시적 트랜잭션(Oracle) | - 트랜잭션 시작을 DBMS에서 자동으로 하며 종료를 사용자가 명시함 - 인스턴스, 세션단위로 설정 가능 |
| 명시적 트랜잭션(SQL Server) | - 트랜잭션 시작과 끝을 사용자가 명시 - Rollback을 만나면 최초의 BEGIN TRANSACTION 시점까지 Rollback |
SAVEPOINT
SAVEPOINT 지정 후 해당 지점으로 ROLLBACK을 시도 시 그 지점까지의 모든 SQL은 ROLLBACK 됨
SAVEPOINT A / ROLLBACK A
23. Top N Query
- 윈도우 함수를 사용하여 상위 N개에 값은 추출할 수 있으나 단일 Query로는 표현이 불가능 (조건에 사용이)
- ROWNUM을 사용한 방식은 ROWNUM 할당 전에 순서대로 데이터를 정렬한 뒤 ROWNUM을 부여하는 게 좋다
- FETCH 절을 사용하면 단일 Query로도 정렬 순서대로 상위 N개에 대한 값을 추출 할 수 있다
- OFFSET 절을 사용하면 FETCH 절에서 NEXT, FISRT로 원하는 n개를 얻을 수 있다.
SQL Server
SELECT TOP N column1, column2, ...
FROM table_name
ORDER BY column_name DESC;Oracle
-- ROWNUM 사용:
SELECT *
FROM (
SELECT column1, column2, ...
FROM table_name
ORDER BY column_name DESC
)
WHERE ROWNUM <= N;-- FETCH FIRST N ROWS ONLY 사용 (Oracle 12c 이상):
SELECT column1, column2, ...
FROM table_name
ORDER BY column_name DESC
FETCH FIRST N ROWS ONLY;
OFFSET (SQL Server, Oracle 동일)
SELECT employee_id, employee_name, salary
FROM employees
ORDER BY salary DESC
OFFSET 10 ROWS FETCH NEXT 5 ROWS ONLY;설명
- ORDER BY salary DESC: 급여 기준으로 내림차순
- OFFSET 10 ROWS: 처음 10개의 행을 건너뜀
- FETCH NEXT 5 ROWS ONLY: 다음 5개의 행을 가져옴
2024.06.04
턱걸이 성공했슴다
대충 전공자이기도 하고 실무자여서 하루 한시간 이내로 2주정도 하다가
시험 전 2~3일만 빡세게 해서 해당 포스팅 작성했더니 합격했네요
